

当我们与大语言模型对话时,输入的自然语言文本(例如 今天用 ChatGPT 写一段 Python 代码)并不能被模型直接理解。模型本质上只能处理数值化的输入,因此需要先经过 Tokenization(分词/词元化) 环节:将原始文本字符串切分成模型可处理的最小语义单元(即 Token),并将每个 Token 转换为对应的数字索引。这一转换得到的 Token 序列,才是模型真正能够“阅读”和计算的输入形式。
什么是 Tokenization
Tokenization,也就是分词,是使用Tokenizer将原始文本字符串拆解为模型可处理的最小语义单元——词元(Token),并将其映射为对应数字索引的过程。
使用 ChatGPT 的 Tokenizer 工具 可以看见 GPT 的分词结果:
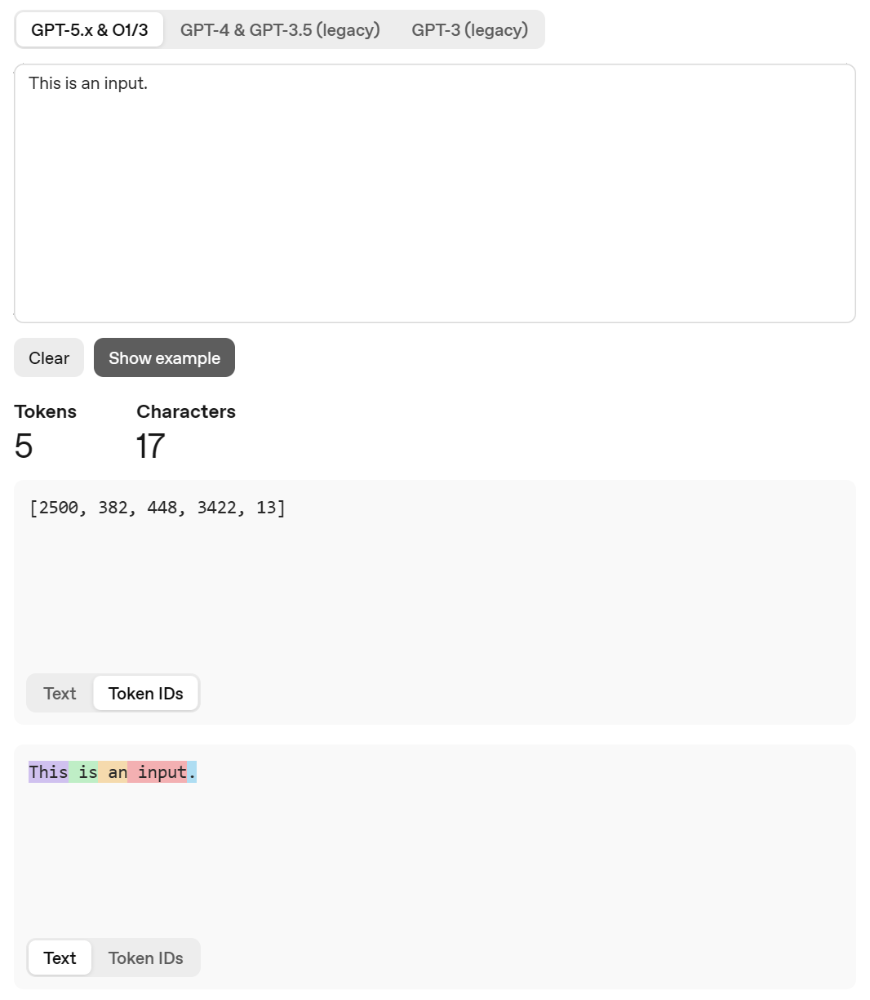
实际上,Tokenizer 就是将字符串映射为一个整数序列,其具体过程:
- 切分:将输入字符串切分为若干 token(子词片段)
- 查表:将每个 token 在词表中(vocabulary)中查找对应的整数 ID
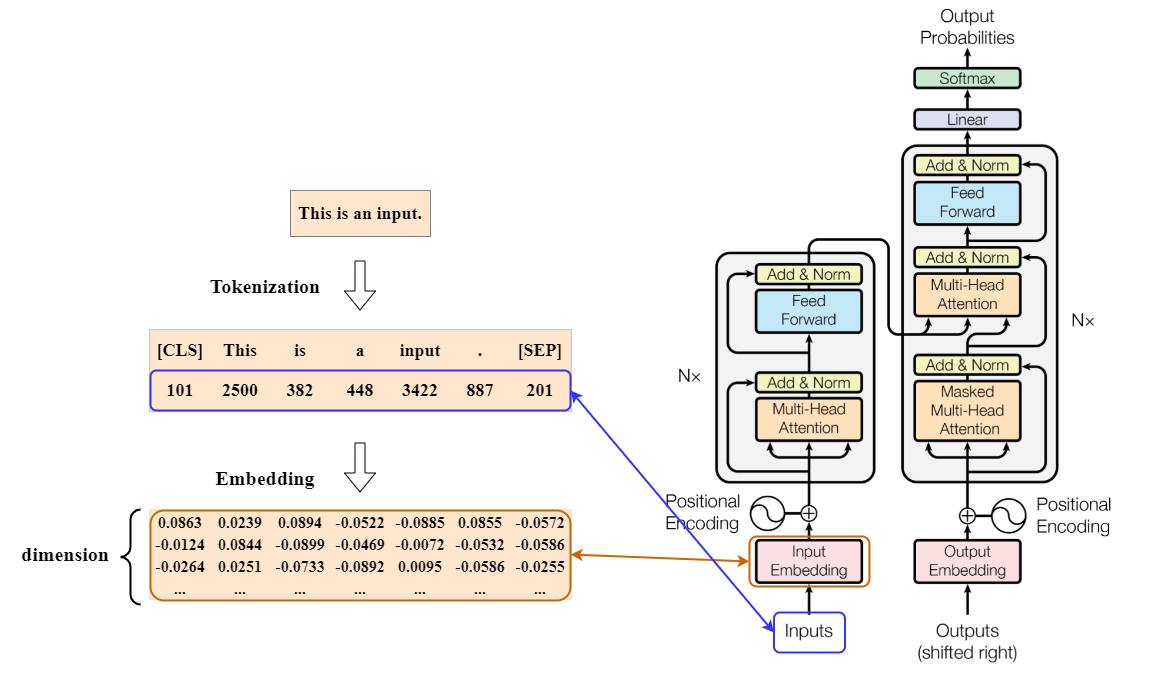
输出一个整数列表,最后再经过一个 Embedding Layer 将token向量化。
Tokenizer 的分词粒度
Tokenizer 的分词粒度主要有三种:字符级、词级和子词级。
这三种粒度各有优劣,现代大模型(如GPT系列、BERT)普遍采用子词级方案,因为它能够在效率和语义之间取得的最佳平衡
字符级分词(Character-level)
以单个字符作为最小的切分单元,如字母、汉字、数字和标点符号。
字符级分词的词表极小,英文只需几十个字母,中文也只需几千个常用字。在理论上,字符级分词能够彻底消除未登录词(Out of vocabulary,OOV)问题,因为任何文本序列均可由有限的字符集合表示,从而具备对无限可能输入的无损覆盖能力。但是,字符级分词的token序列极长,一个单词就会分成好几个token,导致输入序列长度急剧增长,计算成本高。此外,单个字符所承载的语义信息非常有限,模型需要使用更深的网络才能建模出词义信息。
词级(Word-level)
词级分词以单词作为切分单元,通常按空格和标点将文本切分为一个个独立的单词。
例如 ["ChatGPT is amazing"] 切分为 ["ChatGPT", "is", "amazing"] 三个 token。
词级分词方式非常符合人类直觉,且生成的token序列也较短,有利于降低下游模型的计算成本。但词级分词高度依赖与语言自身的边界规则和分词规范。在处理英文等以空格为天然分隔符的语言时,可以依赖空格切分,但对于中文、日文等缺乏显式空格边界的语言,切分边界的判定存在一定的困难。
词级分词需要维护一个庞大的词表以容纳海量的词汇变体、专业术语、以及新生词汇。例如:
model / models/ modeling / model-based
这些单词都作为独立 token,导致词表快速膨胀。
此外,词级分词无法妥善应对未登录词问题(OOV),当推理阶段出现预训练语料中未曾收录的词汇时,模型只能将其映射为统一的未知标记 [UNK] ,导致相关语义信息完全丢失。
还有一个更重要的问题就是,词级分词忽略了词汇在形态层面的内在关联,例如"run"、"running"与"ran"虽在语义上存在派生关系,但在词级分词中作彼此独立的 token,不利于模型捕捉词形变化背后的共性规律。
子词级(Subword-level)
子词级分词是当前大语言模型的主流方案,能够在计算效率和语义表达上取得平衡。
常用词不应该再被切分成更小的token 或 子词,不常用的词或词群应该用子词来表示。
常见的子词分词方法有:
- BPE(Byte-Pair Encoding)
- Byte-Level BPE
- WordPiece
- Unigram
SentencePiece 是一个用于为预训练语料库训练定制化Tokenizer 的代码库。
子词级分词
有些资料也将子词级分词叫做亚词集分词。
下面详细介绍BPE、Byte-Level BPE、WordPiece、SentencePiece、Unigram等几种常见的子词级分词方法
BPE
BPE 算法最早用于通用数据压缩,后来被引入NLP以解决未登录词(OOV)和词表膨胀的问题。
BPE算法从一组基本符号(例如字母和边界字符)开始,迭代地寻找语料库中两个相邻词元,并将它们替换成新的词元,
BPE 算法可以分为两个阶段:训练(词表构建)和推理(tokenization)
训练
BPE Tokenizer 的训练首先计算语料库中使用的单词集合(⚠️ 单词集合,也就是说数据是去重了的),然后再执行如下步骤:
- 初始化:将训练语料中的所有单词拆分为字符,并为每个单词末尾添加一个特殊的结束符号
</w>用于识别单词边界,防止跨单词的字符被错误合并。 - 统计频率:统计当前语料中所有相邻符号对(初始时为字符对)的出现频率。
- 合并最高频符号对:找到频率最高的符号对,将其合并为一个新的子词符号,并更新到词表中。
- 迭代:重复步骤2和3,直到词表大小达到预设的目标,或者剩下的最高频符号对只出现1次为止。
参考 HuggingFace LLM Course 的一个例子:
假设语料库使用了下面这五个词:
"hug", "pug", "pun", "bun", "hugs"
此时的初始词汇表为 ["b", "g", "h", "n", "p", "s", "u"]
假设单词具有以下频率:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
意思是 "hug" 在语料库中出现了 10 次, "pug" 出现了 5 次, "pun" 出现了 12 次, "bun" 出现了 4 次, "hugs" 出现了 5 次。然后将每个单词拆分为字符来开始训练,拆分字符后的语料库是这样的:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
然后开始观察相邻的字符对,可以看出,("u", "g") 在语料库中一共出现了 20次,因此学习到的第一条合并规则是 ("u", "g") -> "ug","ug" 将被添加到词汇表中,且在语料库中合并这一对。在这个阶段结束后,词汇表和语料库将会变成如下形式:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug"]
语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
然后再按照上述规则继续合并,可以观察到 ("u", "n") 在语料库中出现了16次,次数最多,因此学习到的第二个合并规则为 ("u", "n") -> "un",将其添加到词汇表并在语料库中将其合并后,词汇表和语料库将变为以下形式:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
现在最频繁出现的一对是 ("h", "ug") ,因此学习到的合并规则是 ("h", "ug") -> "hug" ,合并后,词汇表和语料库如下所示:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
语料库: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
继续按照上述规则合并,直到达到预设的词汇表大小或者没有可以合并的字符对。
tokenization
完成训练之后,就可以对输入的文本进行分词(tokenization)了,分词的步骤如下:
- 将单词拆分为单个字符
- 根据学习的合并规则,按顺序合并拆分的字符。
例如,在上面的训练步骤中,Tokenizer 学习到了三个合并规则(有先后顺序):
("u", "g") -> "ug"
("u", "n") -> "un"
("h", "ug") -> "hug"
在这种情况下
- 文本
"bug"的分词结果将是["b", "ug"] "mug"的分词结果将是["[UNK]", "ug"],因为字母"m"不在词汇表中。
Byte-Level BPE
Byte-Level BPE 是 BPE 的一种拓展,它将字节作为合并操作的基本符号,能够实现更细力度的分割,且解决了未登录词问题。
具体来说,如果BPE将所有Unicode 字符都视为基本字符,那么包含所有可能基本字符的基本词表将会非常庞大。而将字节作为基本词表可以将基本词库的大小设置为256(2^{8}),同时确保每个基本字符都包含在词汇中。例如,GPT-2的词表大小为50257,包含256个字节的基本词元、一个特殊的文末词元以及通过50,000次合并学习到的词元。通过使用一些处理标点符号的附加规则,GPT-2的Tokenizer可以在不使用 <UNK> 符号的情况下对文本进行分词。
WordPiece
WordPiece 最初应用于语音搜索系统,此后,通常将该算法作为 BERT 的词元分析器。WordPiece 与 BPE 的思想非常相似,都是迭代地合并连续的词元,但在合并的选择标准上略有不同。
为了进行合并,WordPiece 需要先训练一个语言模型,并用该语言模型对所有可能的词元进行评分。在每次合并时,选择使得训练数据似然概率增加最多的词元对。
Google 并没有开源其 WordPiece 算法的官方实现,HuggingFace 在其线上 NLP 课程中提供了一种直观的选择度量算法:一个词元对的评分时根据训练数据库中两个词元的共现计数处以它们各自的出现计数的乘积。计算公式如下所示:
Unigram
Unigram Tokenizer 是一种基于概率模型的子词分词算法。与BPE和WordPiece 这类自底向上的增量合并算法不同,Unigram采用自顶向下的概率筛选策略。它从一个包含大量子词的词表开始,通过评估每个子词对整体模型的重要性,迭代地删除那些不重要的词,最终保留一个最优的子词集合。
其算法细节可以参考:Unigram Tokenization
Tonkenizer 的选用
在大语言模型训练时,虽然直接使用已有的分词器比较方便,但是使用为预训练语料库专门训练的 Tokenizer会更加有效,尤其是对于那些混合了多领域、多语言和多种格式的语料。
最近的大语言模型通常使用SentencePiece 代码库为预训练语料库训练定制化的 Tokenizer,SentencePiece 支持 Byte-Level BPE 和 Unigram 分词。
训练 Tokenizer 时,应重点关注以下几个因素:
- Tokenizer 必须具备无损重构的特性,即其分词结果能够准确无误地还原为原始输入文本
- Tokenizer 应具有高压缩率,即在给定文本数据的情况下,经过分词处理后的词元数量应尽可能少,从而实现更高效的文本编码和存储。
在模型部署后推理时,应使用与训练阶段相同的 Tokenizer,HuggingFace 中的模型附带的 tokenizer.json 就指定了模型使用的分词方法。