
使用 API 接口调用大语言模型时,经常能看见 temperature 这个参数,阿里云白炼平台对 temperature 参数的解释是这样的:

那么 temperature 是如何影响大语言模型的输出结果的呢?
大模型是如何选择下一个 token 的?
要理解 temperature 参数的作用,首先要理解大模型生成文本时的大致过程。
模型在生成每一个 token 时,首先会为词汇表中所有候选词计算一个原始分数(logit),然后通过 softmax 函数将这些 logit 转换为一个 0 到 1 之间的概率分布,这个概率分布满足以下两个特点:
- 每个候选 token 都会对应个概率
- 所有候选 token 的概率之和为1
最终,模型会根据这个概率分布选择下一个 token
temperature 在哪里发挥作用?
temperature 的作用发生在 softmax 计算之前。
它会对 logits 进行缩放,从而改变最终的概率分布形状。
假设模型输出的原始 logtis 向量为 z,词汇表中第 i 个词的 logit 为 z_i,temperature 参数为 T,那么概率第 i 个 token 被选中的概率 P_i 可以表示为:
其中
- P_i:第 i 个 token 被选中的最终概率
- z_i:第 i 个 token 的原始分数(logit)
- T:温度参数
不同 temperature 的影响
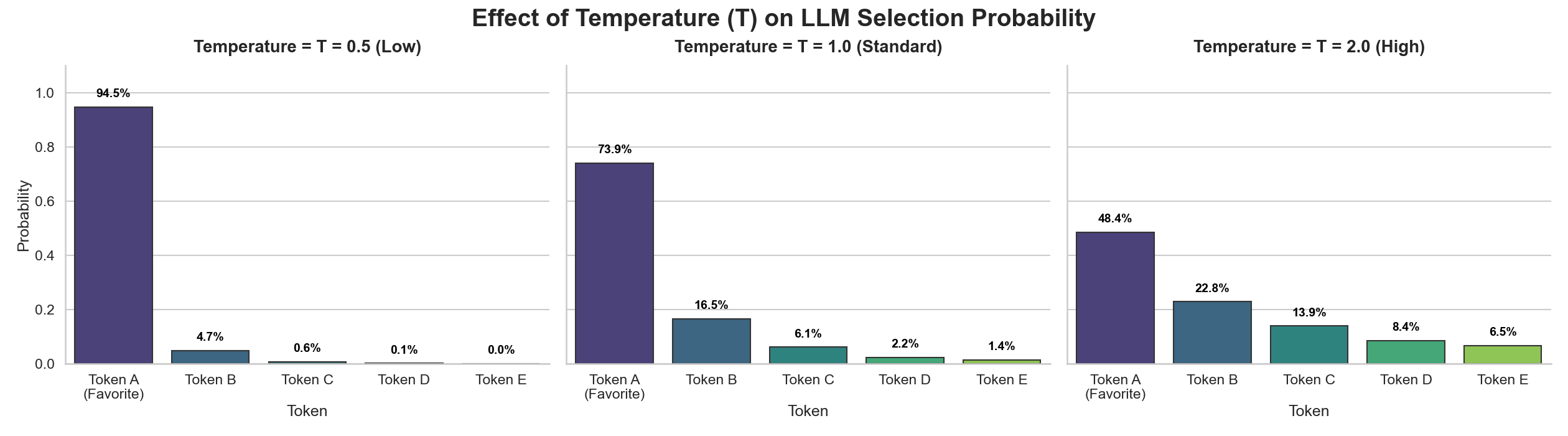
由上面这个图可以看出:
- T<1 时:锐化概率分布,高概率的词被赋予更高的权重,而低概率的词权重则被进一步压低,这使得模型在采样时,几乎总是选中那几个最可能的词,因此输出结果非常稳定和可预测。
- T > 1 时:平滑概率分布,高概率和低概率词之间的差距被缩小,使得那些原本不太可能被选中的词也有机会被选中,增加了输出的随机性和多样性。
那么 T 是如何产生上述影响的呢?
当T < 1 时:除以一个小数相当于放大数值,原本较大的 z_i 会变得更大,原本较小的 z_i 会变得更小。最高概率的词其概率趋近于1,其他词趋近于0,概率分布变得尖锐。
例如,假如模型输出的 logits 为 [1.0, 2.0, 3.0, 4.0],不同温度状态下 softmax 的概率分布为:
- T=1 时,
[0.032059, 0.087144, 0.236883, 0.643914] - T=0.5 时,
[0.002144, 0.015842, 0.117059, 0.864955] - T=0.1时,
[0.000000, 0.000000, 0.000045, 0.999955] - T=2.0 时,
[0.101536, 0.167405, 0.276004, 0.455054]
可以看到,当 T = 1.0 时,概率分布保持标准 softmax 的结果。
当 T = 0.5 时,最大 logit 对应 token 的概率从约 64.4% 提升到了约 86.5%。
当 T = 0.1 时,最大 logit 对应 token 的概率几乎接近 100%,模型几乎一定会选择这个 token。
而当 T = 2.0 时,最大 logit 对应 token 的概率下降到约 45.5%,其他 token 的概率则相应提高,整体分布更加平滑。
这也解释了为什么较低的 temperature 会让模型输出更确定,而较高的 temperature 会让模型输出更多样。
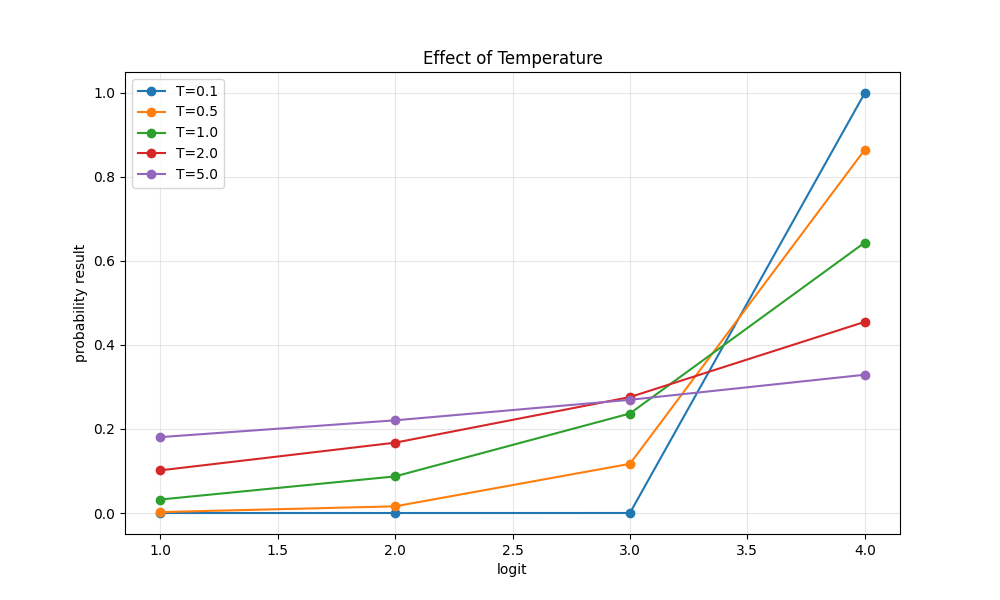
结合上图可以看出,当 T 非常小时,logit 最大的 token 的概率非常趋近于1,而logit最小的元素概率趋近于0,在这样的情况下,模型的输出就非常确定。
当 T 大于1时,概率分布非常平滑。
temperature 与 top_p 的关系
除了 temperature,API 中还经常会出现另一个参数:top_p。
二者都可以影响模型生成结果的随机性,但作用方式不同:
temperature是通过缩放 logits 来改变概率分布的形状;top_p是从概率最高的 token 开始累加,只保留累计概率达到一定阈值的候选 token,再从这些候选 token 中采样。
因此,在实际调参时,通常不建议同时大幅调整 temperature 和 top_p。如果同时修改两个参数,生成结果的变化会更难预测。
更稳妥的做法是:先固定其中一个参数,再调整另一个参数观察效果。