

LATE CHUNKING: CONTEXTUAL CHUNK EMBEDDINGS USING LONG-CONTEXT EMBEDDING MODELS
Abstract
Many use cases require retrieving smaller portions of text, and dense vector-based retrieval systems often perform better with shorter text segments, as the semantics are less likely to be “over-compressed” in the embeddings. Consequently, practitioners often split text documents into smaller chunks and encode them separately. However, chunk embeddings created in this way can lose contextual information from surrounding chunks, resulting in sub-optimal representations. In this paper, we introduce a novel method called “late chunking”, which leverages long context embedding models to first embed all tokens of the long text, with chunking applied after the transformer model and just before mean pooling - hence the term “late” in its naming. The resulting chunk embeddings capture the full contextual information, leading to superior results across various retrieval tasks. The method is generic enough to be applied to a wide range of long-context embedding models and works without additional training. To further increase the effectiveness of late chunking, we propose a dedicated fine-tuning approach for embedding models.
核心贡献:提出一种无需额外训练的 chunk embedding 方法,使每个 chunk embedding 能包含全文上下文信息,从而缓解传统 chunking 中的上下文丢失问题。
即 Late Chunking:不是先把文档切成 chunk 再分别 embedding,而是先让 long-context embedding model 读完整篇文档,得到上下文化 token embeddings,再按 chunk 边界做 mean pooling,从而得到带有全文上下文的 chunk embeddings。
研究背景与问题
传统RAG的chunk策略
在传统 RAG 流程中,长文档会先被切成多个短 chunk,然后每个 chunk 被单独编码成向量,存入向量数据库。这样做的好处是检索粒度细,LLM 后续拿到的文本也短。但问题是:chunk 被独立编码时,它看不到前后文,因此代词、指代词、省略信息、跨段依赖都会丢失。
作者用维基百科中介绍Berlin的词条说明了这一点:
Berlin is the capital and largest city of Germany, both by area and by population. I
ts more than 3.85 million inhabitants make it the European Union’s most populous city, as measured by population within city limits.
The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.
第一句说 “Berlin is the capital...”,后续句子中的 “Its” 和 “The city” 都指 Berlin。但如果这些句子被单独切出来编码,embedding model 不一定知道 “Its” 或 “The city” 指的是 Berlin。结果是:这些 chunk 明明与 Berlin 高度相关,但它们与查询 “Berlin” 的向量相似度偏低。
chunk策略在RAG应用中非常关键,因为RAG的质量高度依赖第一步的检索阶段,如果chunk embedding 没有正确表达语义,检索器就可能召回错误的chunk,一旦召回错误,即使LLM能力再强,也无法在错误依据的基础上给出正确的回答。
现有方法及不足
作者将现有chunk方法分为三种:
- Native Chunk
- Overlapping Chunk
- LLM-based Contextual Embedding
Native Chunk
While simple chunking methods use a fixed token length (Lewis et al., 2020) or split text into units like sentences or paragraphs
文档 → 切 chunk → 每个 chunk 独立输入 embedding model → 得到 chunk embedding
这种方法简单,但最大缺陷是 chunk 之间相互独立,没有语义关联。
Overlapping Chunk
practitioners divide text into overlapping chunks (Safjan, 2023), meaning that the end of one chunk shares some tokens with the beginning of the next chunk.
overlap 策略,即相邻 chunk 共享一部分 token。它可以缓解 chunk 边界附近的信息丢失,但不能解决远距离依赖。
例如,如果某个代词指向几百 token 之前的实体,简单 overlap 很难覆盖。
LLM-based Contextual Embedding
The LLM receives as input the whole document and the target chunk to produce text for augmenting the chunk text with relevant context information before passing it to the embedding model.
另一种方法是用 LLM 读取全文和目标 chunk,然后生成一段上下文说明,把这段说明拼到 chunk 前面,再做 embedding。这种方法可以补充上下文,但缺点是:
- 需要额外LLM调用
- 成本高
- 可能引入生成式模型的不稳定性
Method
Late Chunking
核心思想:先用长上下文 embedding model 对整篇文档做 token-level 编码,再根据 chunk 边界对 token embedding 做局部 mean pooling,从而得到带上下文的 chunk embedding。
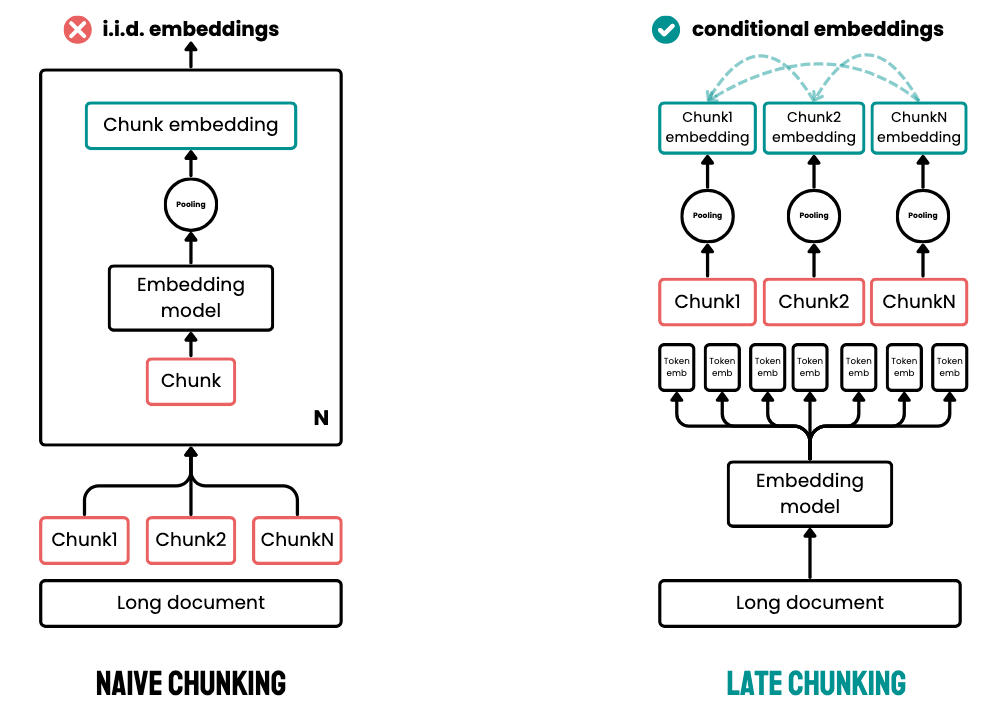
Step1. 确定 chunk 边界
使用某种 chunking strategySS将文档 TT 切分成若干文本chunk:
这里的 chunking strategy 可以是:
PS:这一步只是确定chunk 边界,不是把每个chunk单独送进embedding模型
Step2. 对完整文档进行 tokenization
对全文 TT做tokenization:
其中:
- \tau_j:第 j个token
- o_j:第 j个token对应的字符长度活 offset 信息
因为 chunk 边界通常在字符级或句子级,而 transformer 处理的是 token,所以需要把文本 chunk 边界映射到 token 边界。
Step3. 把完整文档输入 long-text embedding model
将完整token序列输入模型:
其中,v_j \in \mathbb{R}^d,表示第 j 个token的上下文化表示
也就是说,第 j个token的表示不仅取决于它自己,还取决于整片文档上下文
Step4. 将chunk边界映射到token边界
设第 i 个 chunk c_i 的字符范围为 [r_i, s_i],需要找到它对应的 token 范围 [a_i, b_i],可以抽象表示为:
overlaps 指 token 的字符范围与 chunk 的字符范围重叠。
因此第 i 个 chunk 对应的 token 集合为:
Step5. 对每个chunk对应的token embeddings 做 mean pooling
对第 i 个 chunk 内的 token embeddings 求平均:
即:
最后得到所有 chunk embeddings:
最后将这些 embedding 存入向量数据库。
Long Late Chunking
如果文档太长,超过模型的最大输入长度 l_{\text{max}},则使用文中提出的 Long Late Chunking 来处理,其核心原理是使用 macro chunk 解决模型长度限制。 设完整 token 序列为:(\tau_1, \tau_2, \cdots, \tau_m),如果 m > l_{\text{max}},则不能一次性输入模型,此时把文档切分成若干 macro chunks:
其中,q_k - p_k + 1 \le l_{\text{max}},相邻 macro chunks 之间设置 overlap \omega:
对每个 macro chunk 单独进行全文上下文编码:
然后去掉重复 overlap 部分,拼接得到整片文档的近似 contextual token embeddings:(v_1, v_2, \cdots, v_m)。 最后仍按照 Late Chunking 的方式对每个最小 chunk 做 pooling:
实验结果与分析
与其他chunk 策略比较
作者在四个数据集上做了实验,与三种不同的chunk 策略做比较召回精度
- Fixed-Size Boundaries
- Sentence Boundaries
- Semantic Sentence Boundaries
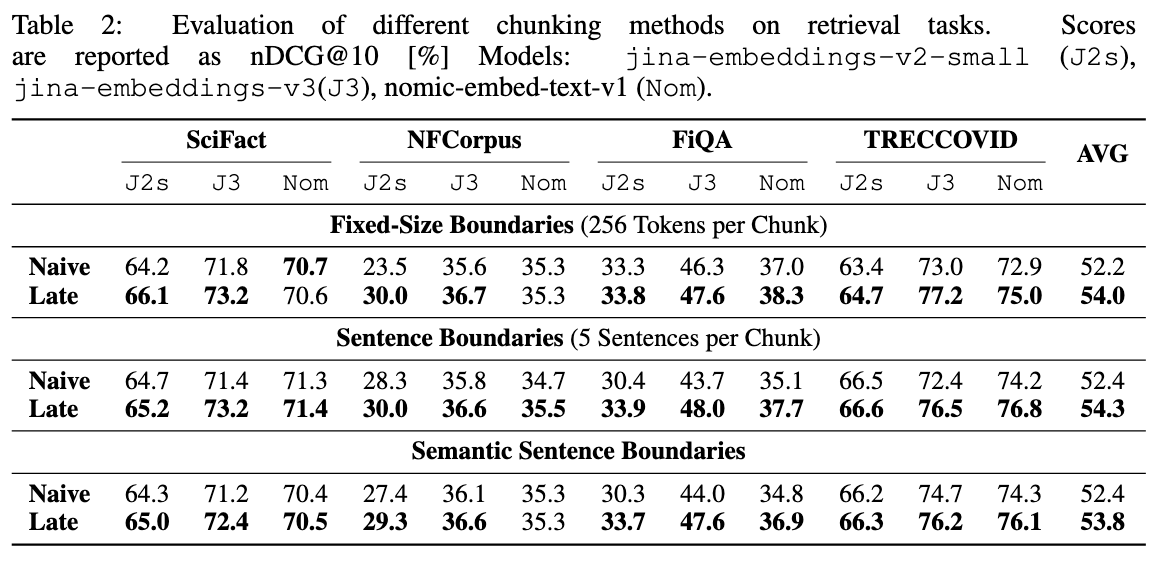
表2结果表明 late chunking 在多个模型和数据集上都有提升。
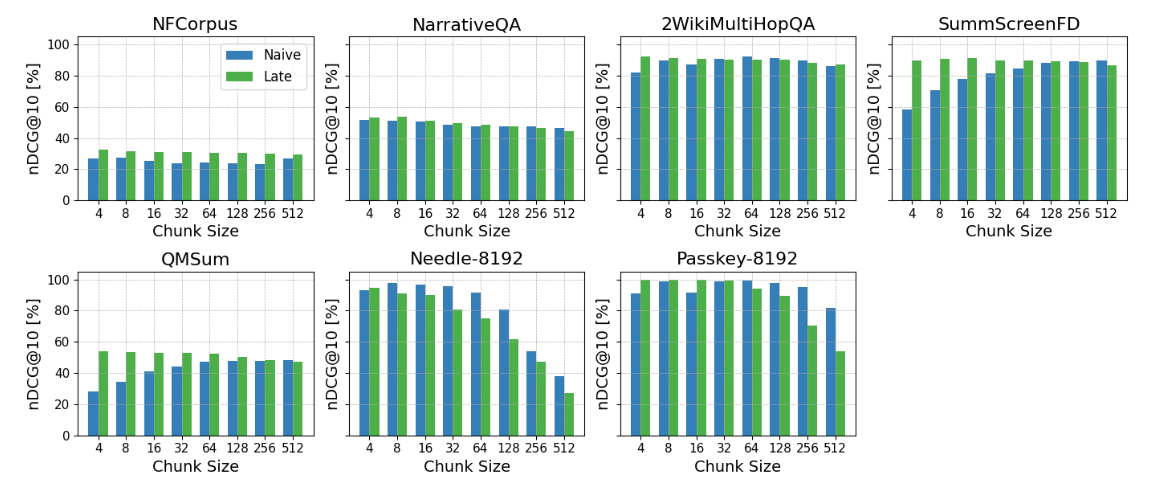
Chunk Size 对 Late Chunking 的影响
chunk size 对 Late Chunking 的影响主要体现在“上下文缺失程度”和“上下文噪声程度”之间的权衡。
当 chunk size 较小时,例如 8、16、32、64 tokens,naive chunking 会因为片段过短而丢失大量上下文,导致 chunk embedding 语义不完整。Late Chunking 先对全文进行编码,再对小 chunk 对应的 token embeddings 做 pooling,因此能够把前后文信息补充进 chunk embedding 中。所以在小 chunk 场景下,Late Chunking 相比 naive chunking 往往优势更明显。
但 Late Chunking 并不是在所有情况下都更好。如果任务中的上下文大多是有用信息,例如长文档 QA、RAG、科研文本或医学文本检索,Late Chunking 可以提升效果;如果任务更像 needle-in-haystack,即答案是孤立短语,周围大段文本都是噪声,那么 Late Chunking 引入全文上下文反而可能稀释局部关键信息,导致表现不如 naive chunking。
chunk 越小,Late Chunking 越能弥补 naive chunking 的上下文缺失;但只有当上下文对理解 chunk 有帮助时,这种优势才会真正体现出来。如果上下文主要是噪声,Late Chunking 可能不占优。
启发
chunk size 应该根据任务类型调整
chunk size 不是越大越好,也不是越小越好。
如果你的任务是:
- 企业知识库问答;
- 法律文档检索;
- 科研论文问答;
- 医学指南检索;
- 金融报告分析;
这些文本通常有很多“该方法”“其结果”“上述条款”“该公司”等上下文依赖。此时可以使用较小 chunk,并用 Late Chunking 补上下文。
但如果你的任务是:
- 精确查找 ID、编号、口令、配置项;
- needle-in-haystack;
- 日志检索;
- 表格字段检索;
- 代码片段定位;
这些场景下局部信息本身可能就是答案,周围上下文反而可能是噪声。此时 naive chunking 或较大的 self-contained chunk 可能更稳。
Overlap 的作用有限
很多 RAG 系统为了防止上下文丢失,会加 chunk overlap。但 Late Chunking 的实验启发是:
overlap 只能补充相邻边界信息,不能真正解决长距离上下文依赖。
比如当前 chunk 里的 “the company” 指向 800 tokens 前的 “ACME Corp”,加 50 tokens overlap 没什么用。
所以实际系统里可以这样理解:
- overlap 适合解决边界切断问题;
- Late Chunking 适合解决语义上下文缺失问题;
- 二者不是同一个问题。
如果已经使用 Late Chunking,overlap 未必还需要很大,否则会增加索引冗余。