
前言
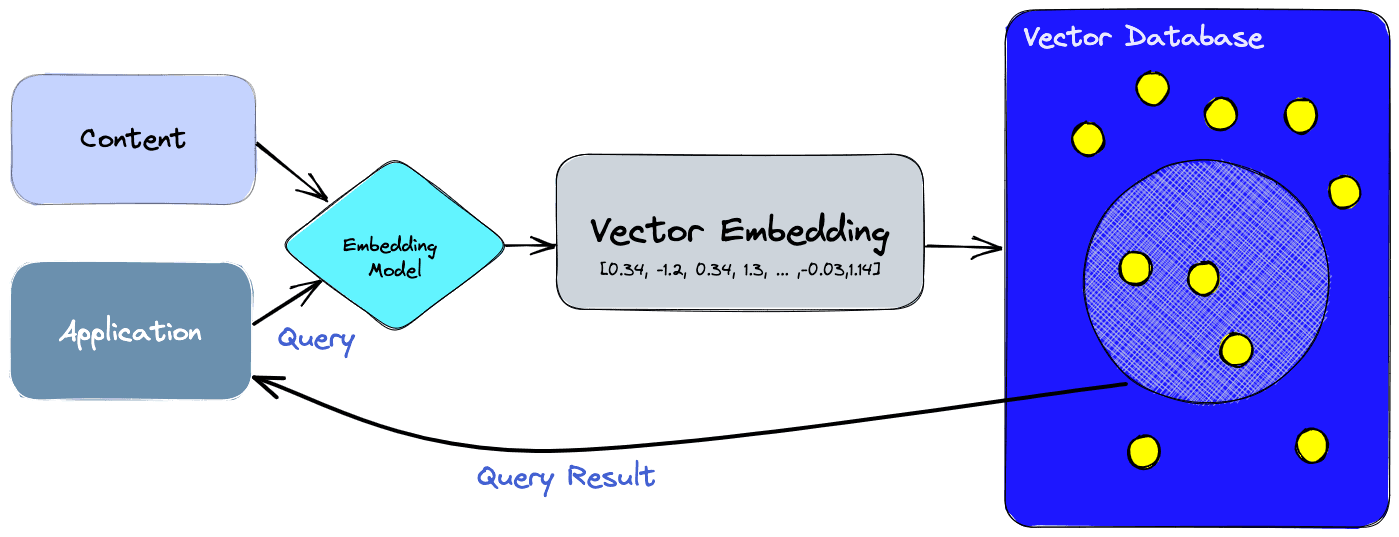
Embedding 模型能够将文本、图像、音频等非结构化数据转换为高维向量,并将其映射到统一的向量空间中。在这个空间里,语义相近的数据通常会拥有更接近的几何位置,从而使计算机能够通过数学计算衡量不同内容之间的相似性。
以文本为例,人类很容易理解“汽车”、“轿车”和“卡车”之间存在明显关联,但对于计算机而言,这些词仅仅是不同的符号序列。尤其是在英文场景下,“automobile”、“car” 与 “truck” 在词形上并不存在明显的联系。Embedding 模型通过学习海量语料中的上下文关系,能够将这些语义相关的词映射到彼此接近的位置,从而捕获其深层语义关联。
这种能力并不仅限于文本。在多模态 AI 领域,Embedding 同样可以将图像、音频、视频等不同类型的数据映射到同一或可对齐的向量空间中,实现跨模态检索与理解。例如:
- 根据文本描述搜索相似图片;
- 根据图片内容查找相关文档;
- 根据音频片段检索对应的视频或文本资料;
- 融合多种模态数据进行联合语义分析。
当数据规模从几万条增长到数百万、数千万甚至数十亿条时,如何高效地存储这些向量,并在海量向量数据中快速找到最相似的内容,成为新的挑战。
这正是向量数据库(Vector Database)诞生的原因。
与传统关系型数据库主要面向结构化数据管理不同,向量数据库专门针对高维向量数据的存储与检索进行优化。除了提供向量及其关联元数据的管理能力之外,其核心价值在于高效执行相似性搜索:面对海量向量数据时,能够快速找到与查询向量最接近的结果,从而为语义搜索、推荐系统、RAG 以及多模态应用提供基础设施支持。
从功能上看,现代向量数据库通常提供以下几项核心能力:
- 向量存储与管理:存储由 Embedding 模型生成的高维向量及其关联元数据,并提供数据的增删改查、过滤和管理能力。
- 向量索引:通过针对高维空间优化的索引结构(如 HNSW、IVF 等),避免全量遍历,大幅提升相似性搜索效率。
- 相似性度量:通过余弦相似度、欧氏距离、点积等距离度量方法量化向量之间的语义接近程度,并结合索引结构高效完成最近邻搜索。
- 混合检索与过滤:结合元数据过滤、关键词检索和向量检索,在保证语义相关性的同时满足业务条件筛选需求。
最近邻搜索
给定一个表示为查询向量 q(如,用户的提问、图片或产品描述的embedding结果),向量搜索的目的是在向量数据集 X=\{{x_1,x_2,\cdots,x_N}\}中找到与 q最相似的 k个向量。这个过程通常被称为k最近邻搜索(k-NN)。
那么应该如何量化这个高维空间中“相似性”呢?以下是几种常用的相似性度量标准:
设两个n维向量,A=(a_1,\cdots,a_n),B=(b_1,\cdots,b_n)
- 欧式距离(L2距离):计算空间中两点之间的直线距离。距离越小说明两者的差异越小。
其中,D是向量的维度。距离越小表示相似度越高。
- 余弦相似度:计算两个向量之间夹角的余弦值,侧重于比较向量之间的方向而非大小,适用于文本数据向量。
其取值范围为 [-1,1],-1表示方向完全相反,1表示方向完全相同,0表示正交(不相关)
- 曼哈顿距离(L1距离):衡量在网格状路径上,沿坐标轴方向移动的总距离。距离越小越相似。
- 点击(Dot Product/Inner Product):综合衡量向量在方向和大小上的差异。值越大越相似。
有了这些相似性度量方法,应该怎么在向量数据库中实现向量检索呢?
最直接的实现方式就是对数据集进行暴力搜索:
- 获取查询向量q
- 计算q与数据集X中每个向量x_i之间的距离
- 对这些距离进行排序
- 返回距离最小的k个向量
尽管暴力方法简单且保证能找到真正的最近邻,但它有一个显著缺点:计算成本高。对于一个包含 N 个向量 (vector),每个向量维度为 D 的数据集,计算查询向量与所有数据集向量之间的距离大约需要 N \times D 次浮点运算。排序还会增加额外开销,通常为 O(N \log N) 或 O(N \log k)。
使用暴力法搜索十亿个 768 维向量,每次查询涉及数万亿次计算。这使得精确 k-NN 对于需要低延迟的实时应用(如检索增强生成(RAG)或交互式语义搜索)来说,在计算上是不可行的。
这个可扩展性瓶颈是近似最近邻(ANN)搜索的主要推动因素。ANN 算法牺牲了找到绝对精确最近邻的保证。它们旨在非常快速地找到极有可能的近邻,通常比精确搜索快几个数量级。它们通过使用巧妙的索引结构和搜索策略来避免将查询向量 (vector)与数据集中的每个向量进行比较,从而实现这一点。
常见向量数据库
主流索引方法:HNSW、IVF、LSH
在向量数据库中,索引对于提升高维度数据空间内搜索操作的效率和速度至关重要。考虑到向量数据库中存储的数据的复杂性和数量,索引机制对于快速定位和检索与查询相关性最高的向量至关重要。
索引方法的核心目标:最大程度地减少每次查询时需要计算距离的向量数量。
HNSW:基于图的索引
HNSW (Hierarchical Navigable Small World) 是目前性能最优异的内存索引算法之一。
IVF:基于空间分割的索引
IVF (Inverted File Index) 的思路非常直观:“物以类聚”。它利用 K-Means 等算法将向量空间划分为多个簇(Cluster)。
LSH:基于哈希的索引
LSH (Locality Sensitive Hashing) 则另辟蹊径,它利用特殊的哈希函数,使得“相似”的向量有更高概率被映射到同一个“桶”中。
乘积量化
参考资料: